Data Storage
Variables - Easy as 1,2,3...
Early computers (1940's) were used only for calculations. They could
be programmed to do complex calculations, including some logical operations
(e.g. if a number is negative, don't try to calculate the square-root). But
the only data stored in the computer was numerical - no pictures
or text.
Three types of numbers were needed: integers (whole numbers),
fixed point decimal (like money that always has 2 decimal places), and
floating point (also called scientific notation, with a mantissa
an exponent.) In modern computers, fixed-point is usually
ignored, as floating point is "good enough". This leads
to round-off errors and salami-slice scams, where the small round-off
errors from millions of calculations are collected into a single bank account,
creating a sizable illegal profit.
Integers are generally stored in binary using two's complement
notation, where the first bit has a large negative value, and all other
bits are positive powers of 2.
Floating point is generally stored with a long binary mantissa
representing an integer value, and a shorter exponent used to adjust
the decimal point appropriately.
Arrays
Modern computers store lots and lots of data - 512 MegaBytes or a GigaByte.
That doesn't mean the RAM is always full, but it could be. To keep
all that data organized, we need much better data-structures than simple
bytes.
An early development in data-structures was the array - a numbered
list of storage locations. The entire RAM of a computer is actually
one big ARRAY! This consists of bytes, meaning that every byte needs
an address (index), or it might be organized into words (e.g.
32 bits), with an address for each word. If there are two many addresses
(e.g. 5 billion) then the address bus must be very larger to transmit
the entire address. This explains why many recent PCs were limited to
4 GB of memory, as the address bus was only 32 bits wide and could only
carry addresses up to 4 billion.
A 2-dimensional array "looks" like a matrix (table), with
rows and columns. But inside the computer, it is actually stored in the
memory in a simple linear array, like this example for a Tic-Tac-Toe board:
|
Internal Storage (for computer)
|
Board[0][0]
|
Mem[0]
|
'X'
|
|
Board[0][1]
|
Mem[1]
|
'O'
|
|
Board[0][2]
|
Mem[2]
|
'X'
|
|
Board[1][0]
|
Mem[3]
|
'O'
|
|
Board[1][1]
|
Mem[4]
|
'X'
|
|
Board[1][2]
|
Mem[5]
|
'O'
|
|
Board[2][0]
|
Mem[6]
|
'O'
|
|
Board[2][1]
|
Mem[7]
|
'X'
|
|
Board[2][2]
|
Mem[8]
|
'X'
|
|
Display (for humans)
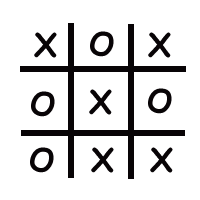
|
So a 2-D array is actually no different than a linear array - it just
uses different commands.
Encodings
Text, graphics, sounds, and other data-types are stored using data-structures
and encoding schemes. This does not mean "secret" codes,
but rather numbering systems that can represent various media.
A simple and common encoding system is ASCII - American Standard Code for
Information Interchange. This is a set of 1-byte values representing letters,
digits, and punctuation marks. The original ASCII system used only 7 bits
to represent 128 different characters. Later this was expanded to 8 bits
for 256 characters. Recently the Unicode system increased the code
size to 16-bits, permitting 65536 different characters, including Persian, Chinese,
Russian, and many other languages.
Graphics can be encoded using Red-Green-Blue intensities, by recording a
byte for each color. That takes care of a single pixel - a more complex
system organizes the data for all the pixels in an image. In a .bmp image,
a simple 2-D array of pixel values represents the image. In compressed
formats like .gif and .jpg, the system is vastly more complex.
Sound can be recorded by sampling the signal, then recording 44000
measurements per second. This creates a data stream that is replayed
sequentially. MP3 compression manages to reduce the basic data
by a factor of 10 by removing sounds that the human ear doesn't actually notice.
The reduced size of the data is attractive, but sophisticated compression
and decompression algorithms are required. Fortunately the decompression
of MP3 files has been embedded into dedicated chips that are small
and cheap and can be included in MP3 players, like the popular I-pod.
Media Files
After sound and video have been captured (with a camera or microphone)
and encoded (changed into numbers), the results need to be stored
(saved) in a media file. A file is a big collection of numbers
that is saved on a disk-drive (possibly a web-server) and then loaded
and displayed. The internal structure (organization) of media files is
usually complex, because after the data has been changed to numbers, the file
is compressed to save space (and shorten download times). So if
you look inside a media file with a hex editor, you probably won't be
able to make sense of the numbers. One exception is the .bmp graphics
format, which is not compressed.
For the loading to work properly, the operating
system must "understand" the encoding scheme. This understanding
is usually provided by a codec (compress/decompress) utility. Some
codecs are already part of the operating system, while others are installed
later as "plug-ins". A common example is Apples's Quick-time
codec.
Data Files
Non-media data, like text, is stored in a data file. In
the simplest case, this is a text-file that can be written, read and
edited using a text-editor like Notepad. Although you CAN access text-files
easily with an editor, you still might have a bit of trouble "understanding"
the data. You might also find it difficult to write in exactly correct
format. Here are three real-world examples:
|
List of English Words
http://www.rg16.asn..../wordlist.txt
systems
systemwide
systole
systolic
sytactic
syzran
syzygial
syzygy
taata
tab
tabac
tabanid
tabard
tabaret
tabbed
tabbies
tabbing
tabby
tabellen
tabernacle
|
CIA World Factbook
http://www.cia.gov
Rank
Country
Population
Date
of Information
~~~~
1
World
6,372,797,742
July 2004
est.
~~~~
2
China
1,298,847,624
July 2004 est.
~~~~
3
India
1,065,070,607
July
2004 est.
~~~~
|
First Names and Nicknames
http://deron.meranda.us/data/nicknames.txt
ANN ROSAENNA 0.20
ANN ROXANNE 0.50
ANN ROXANNA 0.45
ANNIE ANN 0.30
ANNIE ANNE 0.30
ARA ARABELLA 0.20
ARA ARABELLE 0.20
ARCHIE ARCHIBALD 0.50
ARLY ARLENE 0.45
ART ARTHUR 0.90
BABS BARBARA 0.80
BARBIE BARBARA 0.75
BARNEY BARNABAS 0.70
BARNEY BERNARD 0.50
BART BARTHOLOMEW 0.85
BEA BEATRICE 0.70
|
The English words list is easy enough to understand. The CIA population
file is pretty easy to understand, although we might wonder why the squiggly
lines are there. The Nicknames file seems clear enough, although we don't
know what the numbers mean.
Some other text-files are extremely difficult to understand - for example,
HTML source code:
|
<html><head>
<title>Data Storage</title><meta
name="generator" content="Namo WebEditor v4.0">
<style type="text/css">
h4
{background:#ccccff;color:#000066;font-size:110%;font-family:Verdana}
h3
{background:#ccccff;color:#000066;font-family:Verdana}
h2
{color:#000066;font-family:Verdana}
body {font-family:Verdana;
line-height:24px}
</style>
</head>
<body bgcolor="white" text="black"
link="blue" vlink="purple" alink="red">
<h2>Data
Storage</h2><h3><b>Variables - Easy as 1,2,3...</b></h3><p>Early
computers
(1940's) were used only for calculations. They
could be programmed to do <i>
complex</i> calculations,
including some logical operations
..............
|
or a comma-delimited file: http://edoceo.com/utilitas/csv-file-format
Nevertheless, it is possible to write a computer program to "interpret"
each of these files. Indeed, the browser you are using to read
this actually receives HTML codes as input, interprets the meaning of the codes,
and displays the very attractive page that you are reading.
Java Programs for Text Files
We will start with the English Words file, as it is the simplest. The
basic concept of this Java program is the following (pseudo-code):
- Find the text-file on the hard-disk and "open" it.
- Start reading at the beginning
- Start the loop
- read one word
- print it on the screen
- Repeat until you reach the end of the file
- Close the file and quit
In Java, the program looks like this:
import java.io.*;
public class WordReader
{
public static void main(String[] args)
{
new WordReader();
}
public WordReader()
{
try
{
BufferedReader file = new BufferedReader(new FileReader("wordlist.txt"));
do
{
String w = file.readLine();
System.out.println(w);
} while (file.ready());
file.close();
}
catch (IOException ex)
{ System.out.println(ex.toString()); }
}
}
To run this, you will need to download a copy of wordlist.txt
The program reads one word at a time and prints it on the screen. That
takes a long time and probably is not useful.
More Useful Program
The file is intended for use in a Scrabble game, where players make words
from scrambled up letters. For example, a player might use the word "cromble".
Now that might be a misspelled version of "crumble", but maybe
it is actually a word. A "quick" look at the wordlist.txt file
answers the question. But a simpler solution works like this:
- ask the user to input a word
- find the file and open it
- start loop
- read one word from the file
- check whether it matches the user's chosen word
- if it matches then output "Found it"
- repeat until you reach the end of the file
- close the file
The Java program looks like this:
import java.io.*;
public class WordReader
extends EasyApp
{
public static void main(String[] args)
{
new WordReader();
}
public WordReader()
{
String find = input("Type
a word:");
try
{
BufferedReader file = new BufferedReader(new FileReader("wordlist.txt"));
do
{
String w = file.readLine();
if (w.equals(find))
{
System.out.println("Found
it"); }
} while (file.ready());
file.close();
}
catch (IOException ex)
{ System.out.println(ex.toString()); }
}
}
There are many other useful ways to search in the wordlist.txt
file. For example:
- Print all the words that begin with the letter 's' .
- Print all the 2-letter words.
- Print all 7-letter words containing the letter 'k'.
- Print all 7-letter words containing the letters 'a','c','k','s','l'
- Find all words that are ALMOST like the word you want to find -
that
means only one letter is different.
These all require the use of String methods like: charAt(), length(),
indexOf(), etc.